Descubra como o DeepScaleR-1.5B-Preview, um modelo de IA com apenas 1,5 bilhões de parâmetros, supera gigantes como o OpenAI em matemática.
Desempenho Superior em Matemática: O Desafio dos Números
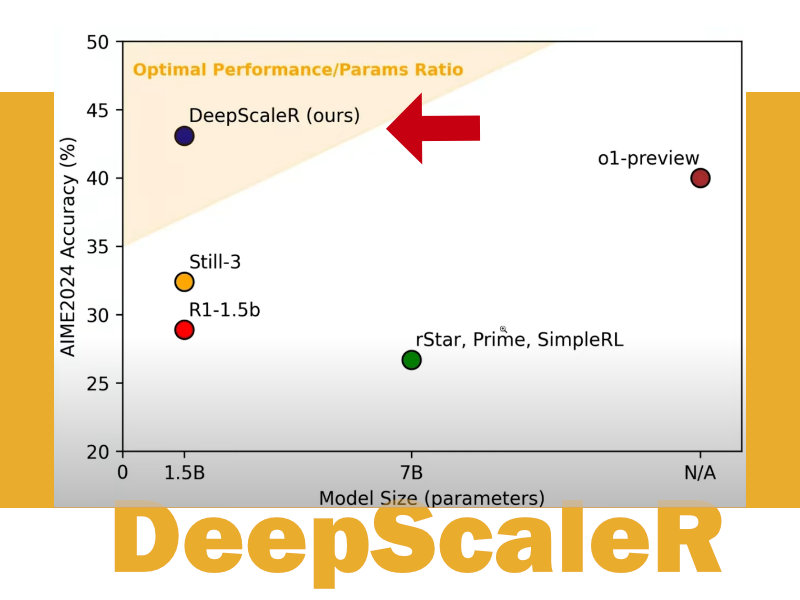
O DeepScaleR-1.5B-Preview atingiu 43,1 pontos no benchmark AIM 2024, ultrapassando os 40,5 pontos do OpenAI 01 Preview, um modelo com potencialmente trilhões de parâmetros. Essa vitória é emblemática por três razões:
- Eficiência em Escala Reduzida: Embora tenha 1/200 do tamanho do GPT-4 (~1,5T parâmetros), o modelo mostra que tamanho não é sinônimo de precisão.
- Versatilidade Matemática: Resolve problemas que vão desde álgebra básica até cálculo multivariado, adaptando-se a diferentes níveis de complexidade.
- Custo-Benefício Radical: Treinado com US$ 4.500, torna acessível o fine-tuning de alta performance para universidades e startups.
Por Que Isso Importa?
A obsessão por modelos cada vez maiores está sendo questionada. O DeepScaleR-1.5B-Preview prova que, com dados de treinamento otimizados e arquitetura focada, é possível competir com gigantes usando frações dos recursos. Isso democratiza o acesso à IA de ponta.
O Segredo por Trás da Tecnologia: Reinforcement Learning e Dados “Distilados”
Reinforcement Learning (RL) com Recompensas Processuais
Ao contrário dos modelos tradicionais que recompensam apenas o resultado final (“acertou ou errou”), o DeepScaleR adota um sistema de recompensa por etapas:
- Exemplo: Se o modelo acerta 5 passos de um problema de 6 etapas, recebe feedback detalhado sobre onde falhou.
- Vantagem: Isso simula o aprendizado humano, identificando erros conceituais (ex.: aplicação incorreta de uma fórmula) em vez de penalizar apenas o erro final.
Supervised Fine-Tuning (SFT) com Dados “Distilados”
O modelo usa dados gerados por LLMs maiores (ex.: GPT-4) para “copiar” seu raciocínio em problemas matemáticos. Esse processo, chamado conhecimento distilado, permite:
- Redução de Custo: Evita o custo proibitivo de treinar modelos gigantes do zero.
- Especialização Rápida: Foca em padrões específicos de problemas matemáticos, ignorando ruídos de dados genéricos.
Detalhes Técnicos que Fazem a Diferença
Portabilidade Radical
Versão F32
- Tamanho: 7 GB.
- Uso Ideal: Pesquisa acadêmica, análises complexas em universidades ou laboratórios.
- Vantagem: Mantém todos os detalhes matemáticos para cálculos precisos.
Versão Quantizada (Q5)
- Tamanho: 1,12 GB – equivalente a um filme em HD.
- Uso Ideal: Dispositivos móveis, IoT (Internet das Coisas) ou áreas remotas sem conectividade.
- Vantagem: Roda em smartphones Android médios e até em Raspberry Pi, democratizando o acesso à IA matemática avançada.
A versão quantizada (Q5) é leve o suficiente para rodar em um smartphone Android médio, abrindo portas para aplicações como:
- Tutores de matemática personalizados em regiões sem internet.
- Professores em zonas rurais podem usar o modelo quantizado para corrigir provas offline.
- Estudantes universitários podem carregar o modelo em um pendrive para resolver problemas de cálculo sem internet.
Open Source: Transparência como Filosofia
A equipe do DeepScaleR liberou publicamente:
- Pesos do modelo (weights).
- Pipeline completo de treinamento.
- Conjunto de dados SFT usado.
Isso permite que pesquisadores independentes validem resultados e façam fork do projeto para novas aplicações (ex.: física ou engenharia).
Comparação com Concorrentes: Uma Nova Era de Eficiência
Modelo: DeepScaleR
- Tamanho: 1,5 bilhões de parâmetros (equivalente a ~0,1% do GPT-4).
- Custo de Treinamento: US$ 4.500 – aproximadamente o preço de um laptop high-end.
- Desempenho AIM 2024: 43,1 pontos.
- Acessibilidade: Open-source, com código e pesos disponíveis publicamente.
OpenAI 01 Preview
- Tamanho: Não divulgado (especula-se centenas de bilhões de parâmetros).
- Custo de Treinamento: Estimado em milhões de dólares.
- Desempenho AIM 2024: 40,5 pontos.
- Acessibilidade: Disponível apenas via API paga.
GPT-4
- Tamanho: ~1,7 trilhões de parâmetros.
- Custo de Treinamento: ~US$ 100 milhões.
- Desempenho AIM 2024: 45,2 pontos.
- Acessibilidade: Acesso restrito a parceiros corporativos.
Análise:
- O DeepScaleR tem custo 22.222x menor que o GPT-4, com desempenho próximo (43,1 vs. 45,2).
- O OpenAI 01 Preview, embora menor que o GPT-4, ainda depende de infraestrutura cara e não é aberto.
Opiniões e Tendências Futuras
A Ascensão dos “Tiny Models”
Especialistas apontam que 2025 pode ser o ano dos modelos especializados e compactos, com vantagens:
- Ecológica: Menos consumo de energia.
- Democrática: Facilita o acesso a países em desenvolvimento.
- Ética: Reduz riscos de vazamento de dados massivos (menos parâmetros = menos superfície de ataque).
Limitações e Críticas
- Precisão Imperfeita: Taxa de acerto de 43% ainda é baixa para aplicações críticas (ex.: diagnósticos médicos).
- Foco Restrito: Não substitui LLMs gerais em tarefas multimodais (ex.: análise de imagens).
Conclusão: O Futuro é Pequeno (e Especializado)
O DeepScaleR-1.5B-Preview não é apenas um modelo — é um manifesto tecnológico. Ele desafia a corrida por modelos cada vez maiores e aponta para um futuro onde eficiência, transparência e acessibilidade são prioritárias.
Para desenvolvedores, é um convite: em vez de depender de APIs caras e fechadas, experimentem construir soluções leves e focadas. A revolução da IA não será apenas maior… será mais inteligente.
Pesquisa, Edição, formatação e finalização:
Werney A. Lima, quinta-feira, 13 de fevereiro de 2025 – 09:49 (quinta-feira)