
Hoje, 24 de julho de 2024, estamos anunciando o Mistral Large 2, a nova geração do nosso modelo principal. Em comparação com seu antecessor, o Mistral Large 2 é significativamente mais capaz na geração de código, matemática e raciocínio. Ele também fornece um suporte multilíngue muito mais forte e recursos avançados de chamada de função.
Benchmarks detalhados
Esta nova geração continua a expandir os limites da eficiência de custos, velocidade e desempenho. O Mistral Large 2 é exposto na la Plateforme e enriquecido com novos recursos para facilitar a criação de aplicações inovadoras de IA.
Mistral Large 2
O Mistral Large 2 tem uma janela de contexto de 128k e suporta dezenas de idiomas, incluindo português, francês, alemão, espanhol, italiano, árabe, hindi, russo, chinês, japonês e coreano, junto com mais de 80 linguagens de programação, como Python, Java, C, C++, JavaScript e Bash.
O Mistral Large 2 foi projetado para inferência de nó único com aplicações de longo contexto em mente – seu tamanho de 123 bilhões de parâmetros permite que ele rode com grande produtividade em um único nó. Estamos lançando o Mistral Large 2 sob a Licença de Pesquisa Mistral, que permite uso e modificação para pesquisa e usos não comerciais. Para uso comercial do Mistral Large 2 que requeira implantação própria, uma Licença Comercial Mistral deve ser adquirida através de contato conosco.
Desempenho geral
O Mistral Large 2 estabelece uma nova fronteira em termos de desempenho/custo de atendimento nas métricas de avaliação. Em particular, no MMLU, a versão pré-treinada atinge uma precisão de 84,0% e estabelece um novo ponto na fronteira de desempenho/custo de modelos abertos.
Código e Raciocínio
Seguindo nossa experiência com Codestral 22B e Codestral Mamba, treinamos o Mistral Large 2 em uma proporção muito grande de código. O Mistral Large 2 supera vastamente o antigo Mistral Large e se iguala a modelos líderes como GPT-4o, Claude 3 Opus e Llama 3 405B.

Um esforço significativo também foi dedicado a aprimorar as capacidades de raciocínio do modelo. Uma das principais áreas de foco durante o treinamento foi minimizar a tendência do modelo de “alucinar” ou gerar informações plausíveis, mas factualmente incorretas ou irrelevantes. Isso foi alcançado por meio de ajustes finos no modelo para torná-lo mais cauteloso e perspicaz em suas respostas, garantindo que forneça saídas confiáveis e precisas
Além disso, o novo Mistral Large 2 é treinado para reconhecer quando não pode encontrar soluções ou não tem informações suficientes para fornecer uma resposta confiante. Esse compromisso com a precisão se reflete no desempenho aprimorado do modelo em populares benchmarks matemáticos, demonstrando suas aprimoradas habilidades de raciocínio e resolução de problemas.



Acompanhamento de instruções e alinhamento
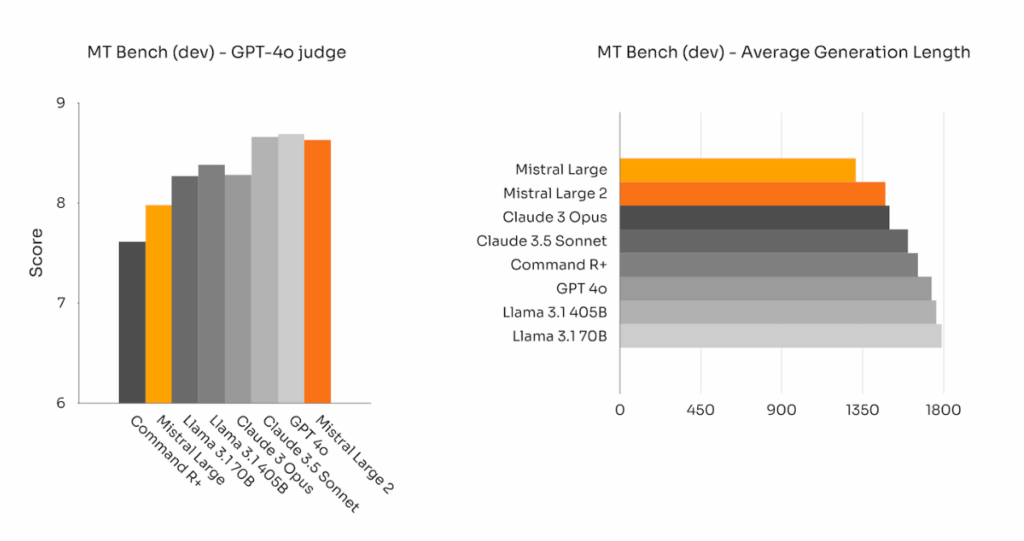
Melhoramos drasticamente as capacidades de acompanhamento de instruções e conversacionais do Mistral Large 2. O novo Mistral Large 2 é particularmente melhor em seguir instruções precisas e lidar com conversas longas de múltiplas etapas. Aqui estão os resultados de desempenho do Mistral Large 2 nos benchmarks MT-Bench, Wild Bench e Arena Hard:

Em alguns benchmarks, gerar respostas longas tende a melhorar os scores. No entanto, em muitas aplicações de negócios, a concisão é primordial – gerações curtas do modelo facilitam interações mais rápidas e são mais eficientes em termos de custos para inferência. É por isso que investimos muito esforço para garantir que as gerações permaneçam sucintas e diretas sempre que possível. O gráfico abaixo reporta o comprimento médio das gerações de diferentes modelos em questões do benchmark MT Bench:
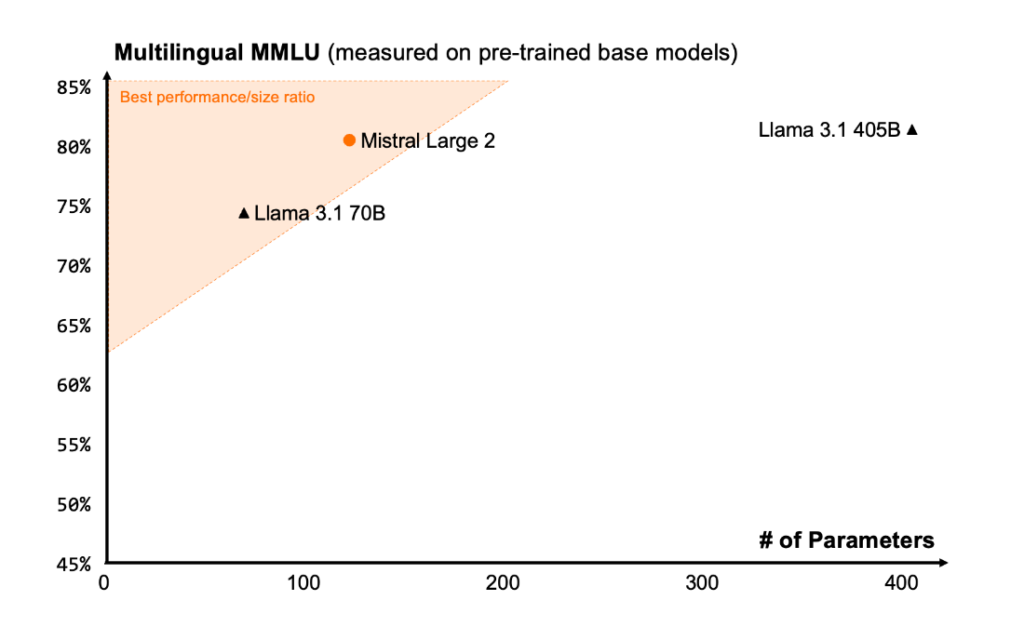
Diversidade linguística
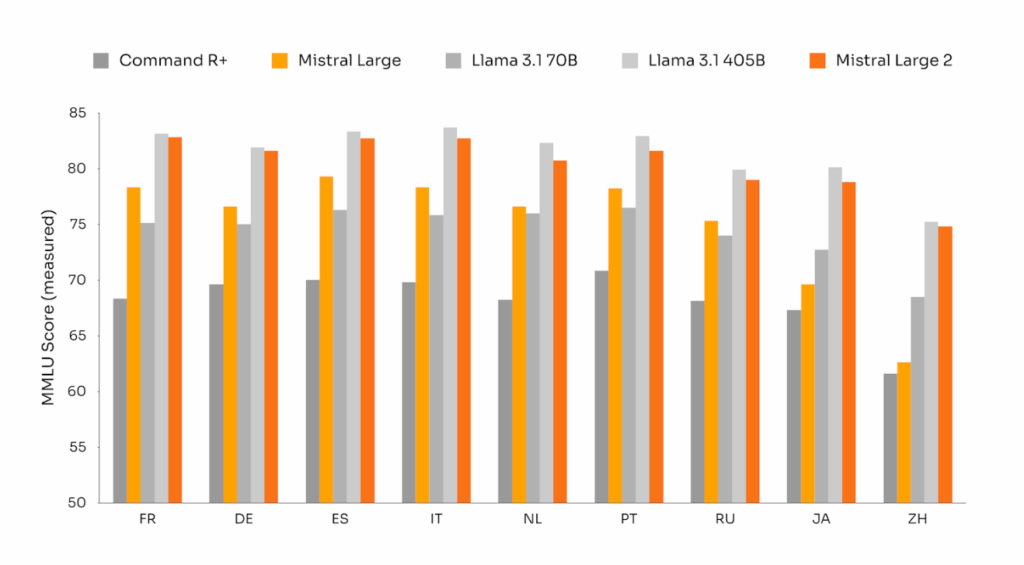
Uma grande fração dos casos de uso comerciais hoje envolve trabalhar com documentos multilíngues. Enquanto a maioria dos modelos é centrada em inglês, o novo Mistral Large 2 foi treinado em uma grande proporção de dados multilíngues. Em particular, ele se destaca em inglês, francês, alemão, espanhol, italiano, português, holandês, russo, chinês, japonês, coreano, árabe e hindi.
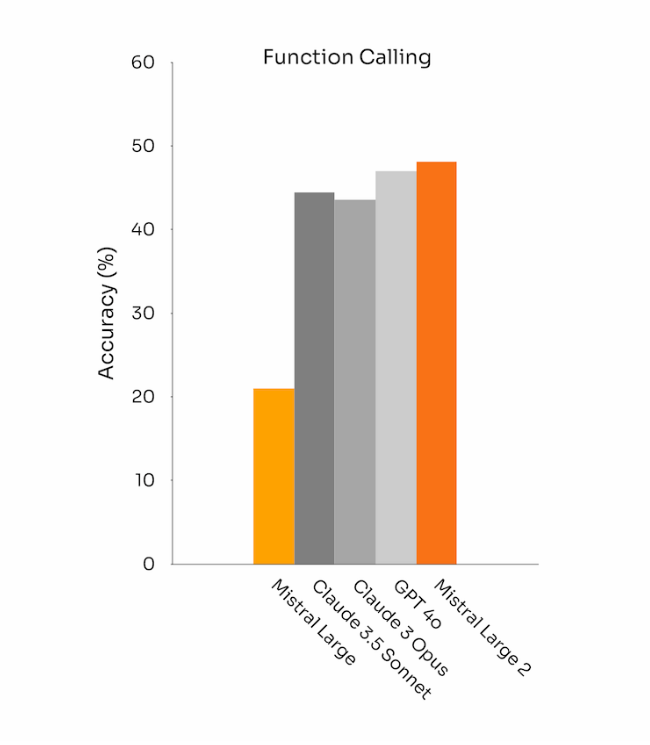
Uso de ferramentas e chamada de funções
O Mistral Large 2 está equipado com aprimoradas habilidades de chamada e recuperação de funções e passou por treinamento para executar chamadas de função paralelas e sequenciais com proficiência, permitindo que sirva como o mecanismo de força de aplicações comerciais complexas.
Experimente o Mistral Large 2 na la Plateforme
Você pode usar o Mistral Large 2 hoje via la Plateforme com o nome mistral-large-2407, e testá-lo no le Chat. Está disponível na versão 24.07 (um sistema de versionamento AA.MM que estamos aplicando a todos os nossos modelos), e o nome da API é mistral-large-2407. Os pesos para o modelo instruct também estão disponíveis e hospedados no HuggingFace.
Estamos consolidando a oferta na la Plateforme em torno de dois modelos de uso geral, Mistral Nemo e Mistral Large, e dois modelos especializados, Codestral e Embed. À medida que descontinuamos progressivamente os modelos mais antigos na la Plateforme, todos os modelos Apache (Mistral 7B, Mixtral 8x7B e 8x22B, Codestral Mamba, Mathstral) permanecem disponíveis para implantação e ajuste fino usando nossos SDKs mistral-inference e mistral-finetune.
A partir de hoje, estamos estendendo os recursos de ajuste fino na la Plateforme: eles agora estão disponíveis para Mistral Large, Mistral Nemo e Codestral.
Acesso aos modelos Mistral através de provedores de serviços de nuvem
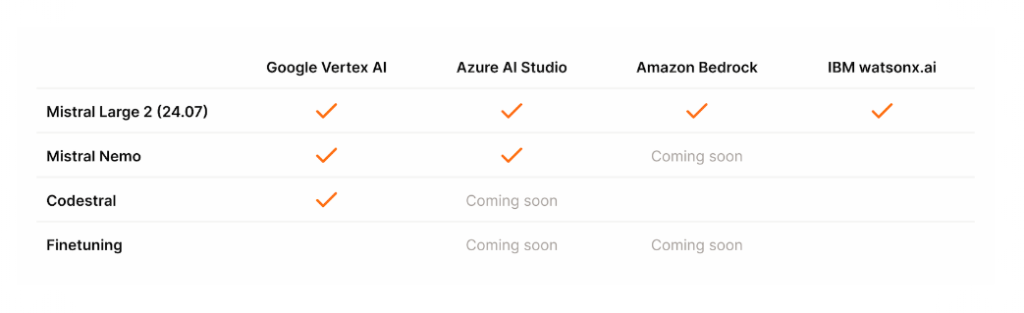
Temos orgulho em nos associar com líderes provedores de serviços de nuvem para levar o novo Mistral Large 2 a uma audiência global. Em particular, hoje estamos expandindo nossa parceria com a Google Cloud Platform para trazer os modelos da Mistral AI para o Vertex AI por meio de uma API Gerenciada. Os melhores modelos da Mistral AI agora estão disponíveis no Vertex AI, além do Azure AI Studio, Amazon Bedrock e IBM watsonx.ai.
Cronograma de disponibilidade dos modelos da Mistral AI
Este post é uma tradução do post oficial da Mistral: https://mistral.ai/news/mistral-large-2407/
Werney Lima, julho 27, 2024 (Sábado) – 10:17 hrs.