
Este artigo é uma tradução do conteúdo do site oficial da Mistral AI.
Mistral AI continua sua missão de entregar os melhores modelos abertos à comunidade de desenvolvedores.
Hoje, 11 de dezembro de 2023, a equipe tem o orgulho de lançar o Mixtral 8x7B, um modelo de mistura esparsa de especialistas (SMoE) de alta qualidade com pesos abertos. Licenciado sob Apache 2.0. Mixtral supera o Llama 2 70B na maioria dos benchmarks com inferência 6x mais rápida. É o modelo aberto mais forte com uma licença permissiva e o melhor modelo geral em relação às compensações custo/desempenho. Em particular, ele corresponde ou supera o GPT3.5 na maioria dos benchmarks padrão.
Mixtral tem os seguintes recursos.
- Ele lida normalmente com um contexto de 32 mil tokens.
- Ele lida com inglês, francês, italiano, alemão e espanhol.
- Mostra forte desempenho na geração de código.
- Ele pode ser ajustado em um modelo de seguimento de instruções que atinge uma pontuação de 8,3 no MT-Bench.
Empurrando a fronteira de modelos abertos com arquiteturas esparsas
Mixtral é uma rede esparsa de mistura de especialistas. É um modelo somente decodificador onde o bloco feedforward escolhe um conjunto de 8 grupos distintos de parâmetros. Em cada camada, para cada token, uma rede de roteadores escolhe dois desses grupos (os “especialistas”) para processar o token e combinar sua saída de forma aditiva.
Essa técnica aumenta o número de parâmetros de um modelo enquanto controla o custo e a latência, pois o modelo usa apenas uma fração do conjunto total de parâmetros por token. Concretamente, o Mixtral tem um total de 46,7 bilhões de parâmetros, mas usa apenas 12,9 bilhões de parâmetros por token. Portanto, ele processa entradas e gera saídas na mesma velocidade e pelo mesmo custo que um modelo 12,9B.
A Mixtral é pré-treinada com dados extraídos da Web aberta – treinamos especialistas e roteadores simultaneamente.
Desempenho
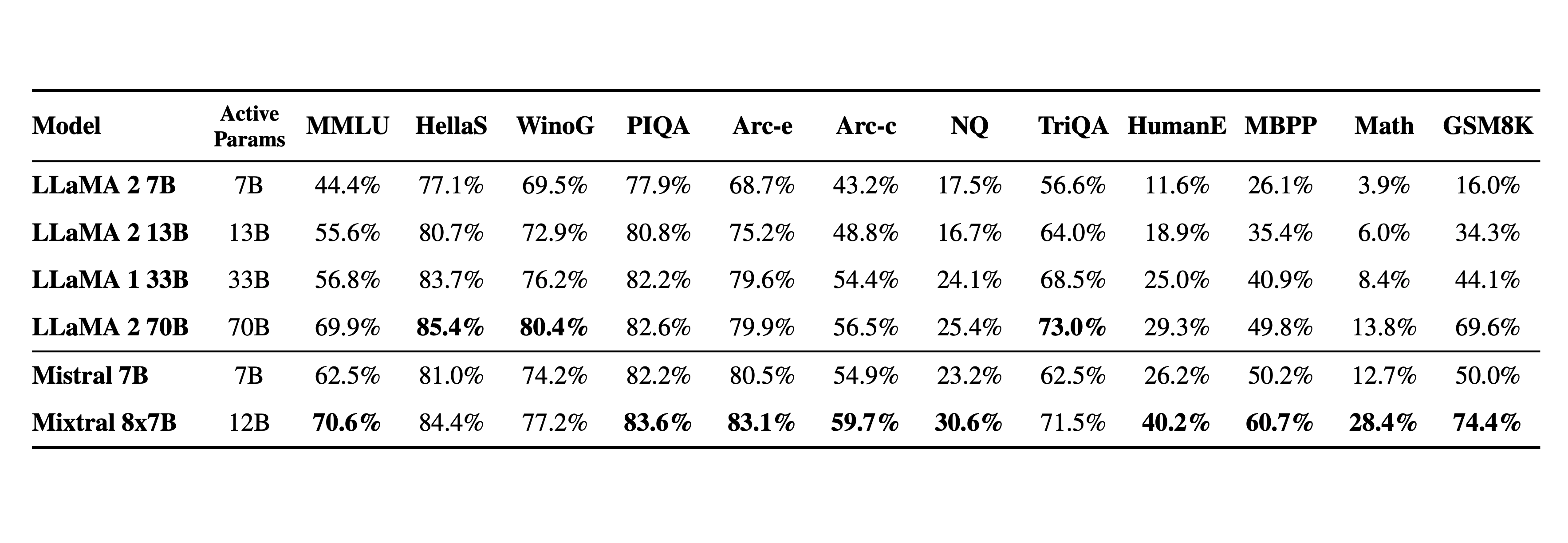
Comparamos o Mixtral com a família Llama 2 e o modelo básico GPT3.5. Mixtral iguala ou supera Llama 2 70B, bem como GPT3.5, na maioria dos benchmarks.
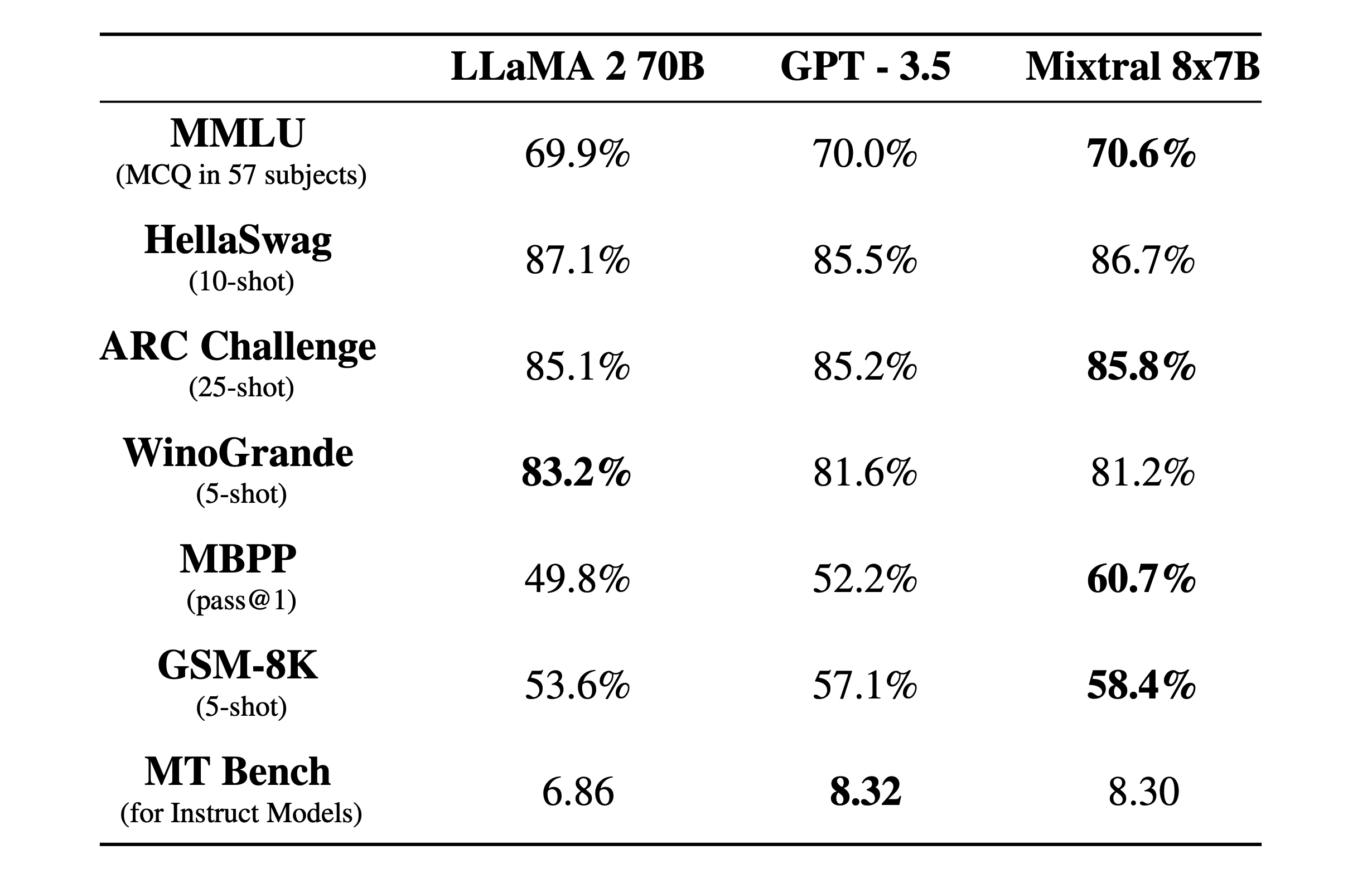
Na figura a seguir, medimos a compensação entre qualidade e orçamento de inferência. Mistral 7B e Mixtral 8x7B pertencem a uma família de modelos altamente eficientes em comparação com os modelos Llama 2.
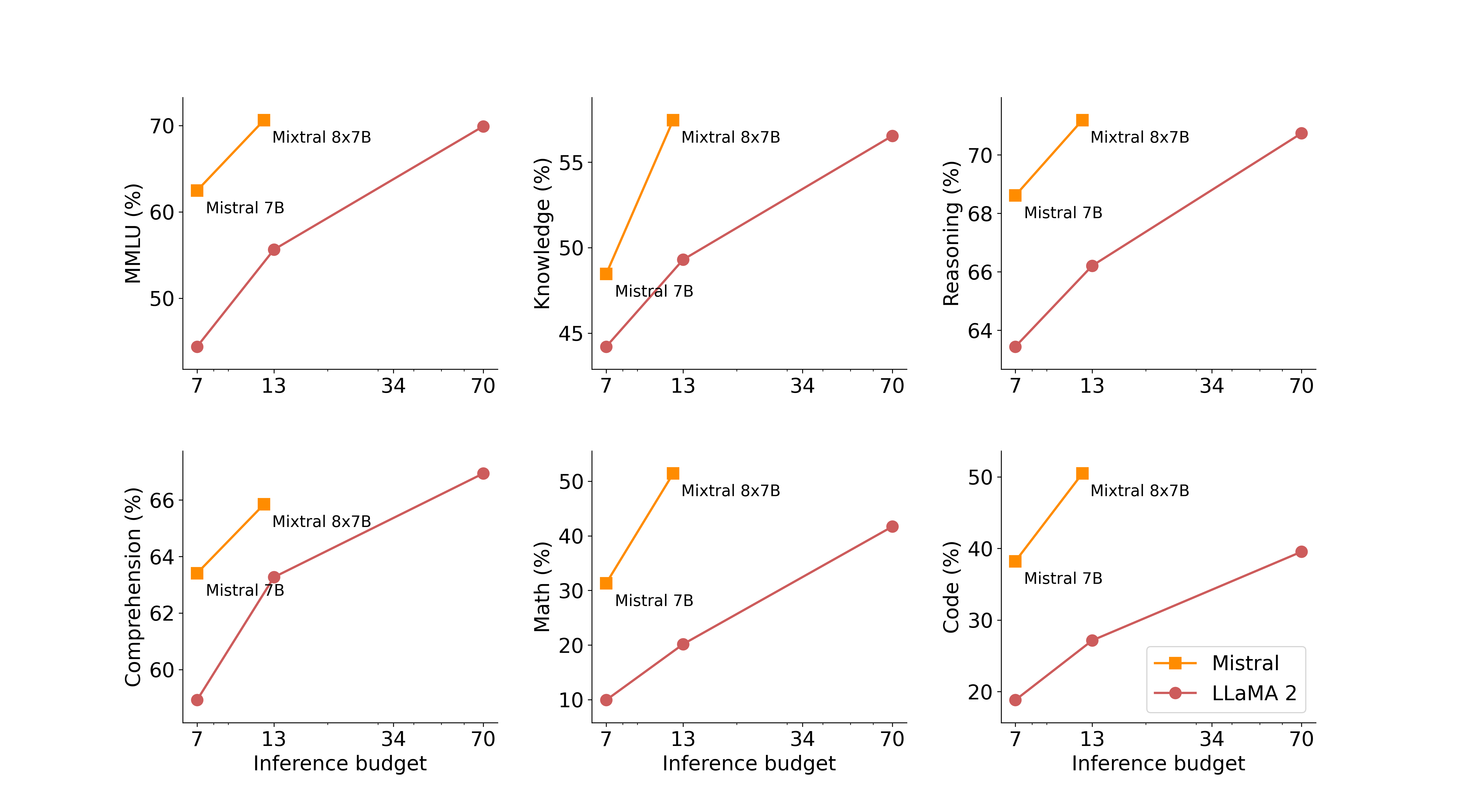
A tabela a seguir fornece resultados detalhados da figura acima.
Alucinações e preconceitos. Para identificar possíveis falhas a serem corrigidas por meio de ajuste fino/modelagem de preferência, medimos o desempenho do modelo base em BBQ/BOLD.
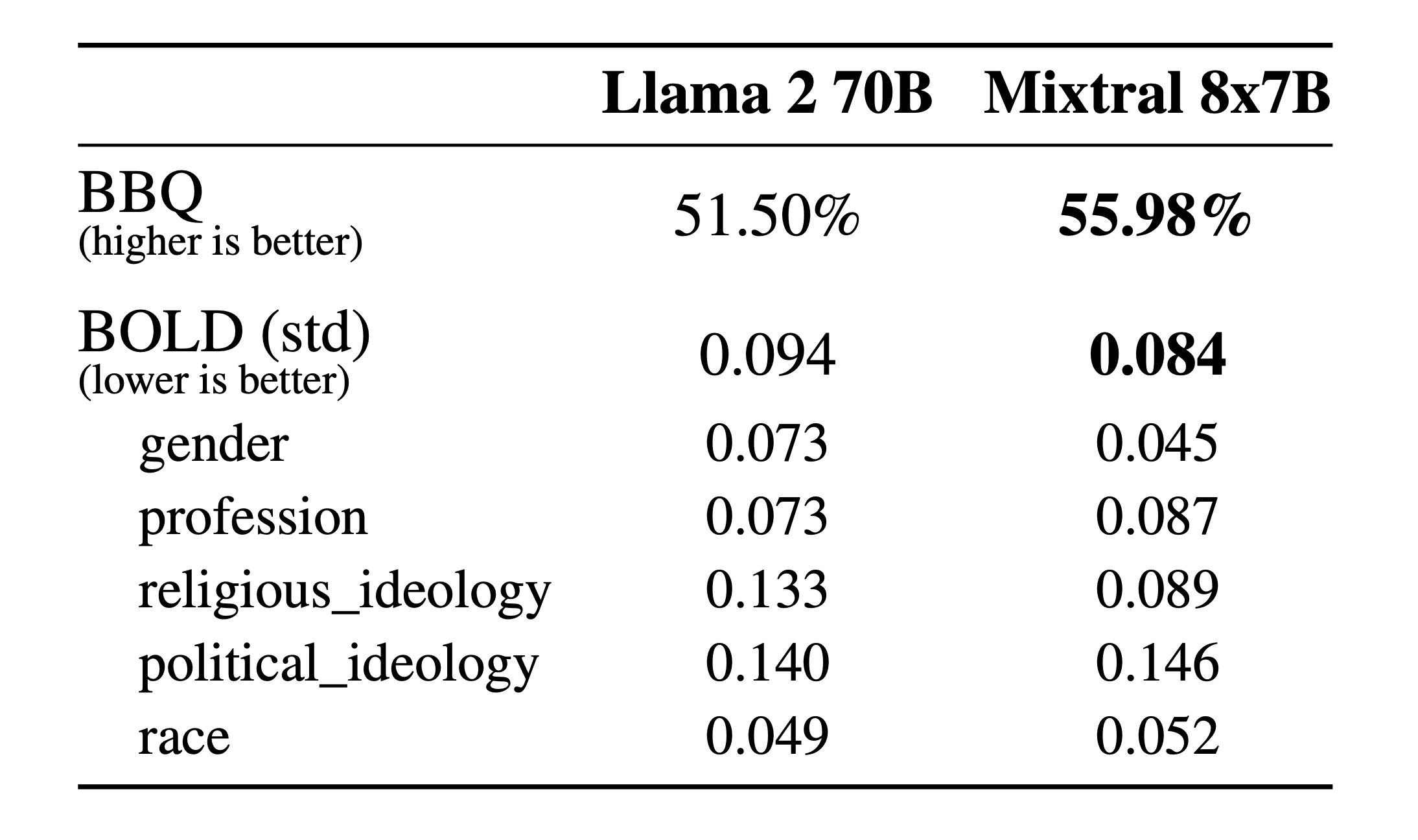
Comparado ao Llama 2, o Mixtral apresenta menos viés no benchmark BBQ. No geral, o Mixtral exibe sentimentos mais positivos do que o Llama 2 no BOLD, com variações semelhantes dentro de cada dimensão.
Linguagem. Mixtral 8x7B domina francês, alemão, espanhol, italiano e inglês.
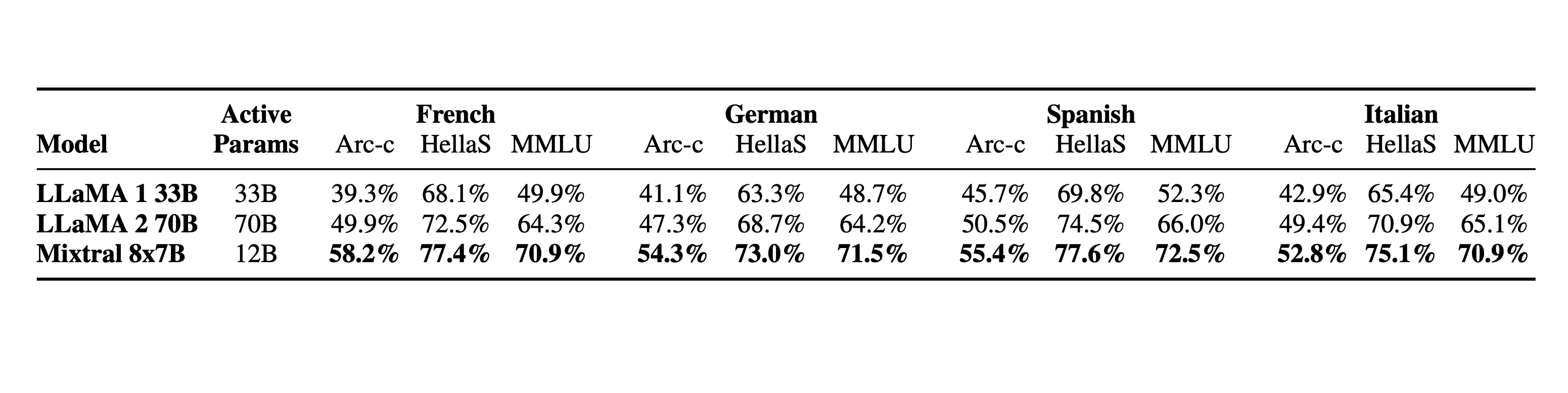
Modelos instruídos
Lançamos o Mixtral 8x7B Instruct junto com o Mixtral 8x7B. Este modelo foi otimizado por meio de ajuste fino supervisionado e otimização de preferência direta (DPO) para acompanhamento cuidadoso das instruções. No MT-Bench, atinge pontuação de 8,30, tornando-se o melhor modelo open source, com desempenho comparável ao GPT3.5.
Nota: Mixtral pode ser solicitado a proibir algumas saídas da construção de aplicativos que exigem um forte nível de moderação, como exemplificado aqui . Um ajuste de preferência adequado também pode servir a esse propósito. Lembre-se de que, sem esse aviso, o modelo apenas seguirá as instruções fornecidas.
Implante o Mixtral com uma pilha de implantação de código aberto
Para permitir que a comunidade execute Mixtral com uma pilha totalmente de código aberto, enviamos alterações ao projeto vLLM, que integra kernels Megablocks CUDA para inferência eficiente.
Skypilot permite a implantação de endpoints vLLM em qualquer instância na nuvem.
Use Mixtral
Atualmente estamos usando Mixtral 8x7B por trás de nosso endpoint mistral-small , que está disponível em beta . Registre-se para obter acesso antecipado a todos os endpoints generativos e incorporados.
_________
Fonte: https://mistral.ai/news/mixtral-of-experts/